Ethereum.org 2.0 Mauve Paper

# Introduction
過去十年間、Bitcoin 、Namecoin や Ethereum といったプロジェクトは、暗号理論による合意形成ネットワークを築き上げてきました。それは非中央集約型のシステムを発展させる次の段階にあるものであり、非中央集約型のシステムは、データストレージやメッセージサービスから、状態をもつ任意のアプリケーションの全基盤を管理するものまでを使用の範疇とします。
提案され、実装に至るアプリケーションとしては、次のようなものがあります。
グローバルにアクセス可能な決済から、金融商品、予測市場、個人情報登録や実世界上の財産所有やCAシステム、supply chain を用いた産地情報のトラッキングシステムでさえもあります。
Over the past decade, projects such as Bitcoin, Namecoin and Ethereum have shown the power of cryptoeconomic consensus networks in bringing about the next stage in advancing decentralized systems, expanding their scope from data storage and messaging services to managing the full back-end of arbitrary stateful applications. Proposed and implemented applications for such systems range from simple globally accessible payments to financial contracts, prediction markets, registration of identity and real world property ownership, certificate authority systems, and even tracking manufactured goods through the supply chain.
しかし、これらの非中央集約型システムは、ひどく非効率であります。非効率性の元となるものは、大きく以下の2つに分けれます。
- Proof of work は多大な電力を消費します。Bitcoin で言えば、これはアイルランドの総電力量に匹敵します。
- 各ネットワークにおけるフルノードがトランザクション毎に全状態及びプロセスを保持することから、唯一のフルノードにおけるネットワークより
たくさんのトランザクションを実行することは不可能です。
However, these decentralized systems remain painfully inefficient. Two major sources of this inefficiency are:
- The most common consensus mechanism, proof of work, consumes large amounts of electricity. In fact, the largest platform using this mechanism, Bitcoin, consumes as much electricity as the entire country of Ireland.
- Because each full node in the network must maintain the entire state and process every transaction, the network can never process more transactions than a single full node is capable of processing.
我々は、これら二つの問題に対して、proof of stake と sharding をくっつけることで、一つの解決策を提案します。Proof of stake は2012年に生まれ、修正がなされ、現在のアルゴリズムはそれ以前のシステムにおける欠陥を解決し、block finalization (第3節) や高速な light client のサポート(第3.2節)といったような proof of work にはない新しい性質を保持しています。Proof of stake は「仮想採掘」であるとみなすことができます。proof of work では
採掘者は実世界のドルを、コンピュータが統計学的乱数によるブロック生成に消費する、電力に対して費やしますが、proof of stake においては、ユーザはドル紙幣をシステム内部の仮想コインに費やし、そして、「仮想コイン」を「仮想コンピュータ」に変換するための ある内部プロトコルのメカニズムを使います。それはある擬似内部プロトコルメカニズムであって、統計学的乱数下で、おおよそ、費やしたコストに見合うだけの比率で、ブロックを生成し、
電力消費なしに出力を製造し続けます。
We propose a solution to these two problems combining proof of stake and sharding. Proof of stake has existed since 2012, but this modified algorithm solves flaws in previous systems and introduces new desirable properties not present in proof of work such as block finalization (Section 3) and fast light client support (Section 3.2). Proof of stake can be thought of as "virtual mining". In proof of work, miners spend real-world dollars for real computers expending electricity to stochastically produce blocks at a rate roughly proportional to the cost expended, whereas in proof of stake, users spend real-world dollars for virtual coins inside the system, and then use an in-protocol mechanism to convert the virtual coins into virtual computers, which are simulated in-protocol to stochastically produce blocks at a rate roughly proportional to the cost expended---replicating the outcome without the electricity consumption.
Sharding もまた空想のものでなく、ここ10年にわたり分散データベースのデザインにおいて存在するものです。しかし、世界規模の決済システムとしてスケールするブロックチェーンへの応用に対する研究はほぼ皆無です。その基本的なアプローチとは、scalability をある architecture を通して改善するもので、ある architecture とは、その内部では、グローバル検証者のリストに載ったノードが、ランダムに、準独立な “ shards(ガラスの破片) “ と結びつけられているものです。各 shard は、全状態のことなる部分を同時に処理し、そのため、仕事を全員でするというよりかはむしろ、ノードの幾つかに分けて分担して仕事を行います。
Sharding is also not novel and has existed in distributed database design for over a decade. But there has been little research into its application for scaling blockchains. The basic approach is to improve scalability via an architecture in which nodes from a global validator set (in our case created through proof of stake bonding) are randomly assigned to one or more semi-independent "shards". Each shard processes transactions in different parts of the state in parallel, thereby ensuring that the work is partitioned across subsets of nodes rather than the work being done by everyone.
望ましい7つの性質:
We have seven desirable properties:
1. (POS) Efficiency via proof of stake.
合意形成は採掘なしでセキュリティの確保したものであるべきであり、そのため電力浪費の大幅な削減とともに、無制限で莫大なETH の発行手数料の削減をします。
Consensus should be secured without mining, thereby greatly reducing electricity waste as well as reducing the large and indefinite ongoing ETH issuance (as block rewards no longer must compensate for the large energy expenditure).
2. (FB) Fast block time.
ブロック生成時間は最大限に速くし、しかしセキュリティに関する妥協はしないというものです。
The block time should be maximally fast, though without compromising security.
3. (F) Finality.
一度ブロックが発行されると、ある一定期間後にブロックは “ finalize “され、
結果として、大多数の検証者は、そのブロックを持たないすべての履歴上でのETH の残高を失います。これは望ましい性質です。というのは、多数勢による衝でさえ、自分自身のデポジットを犠牲なしに51%攻撃ができなくなります。
Once a block is published, after an amount of time the block is “finalized”, with the result that a large portion of validators lose their entire ETH deposits (think: 10 million ETH) in all histories that do not have that block. This is desirable because it means that even majority collusions cannot conduct medium or long-range 51% attacks without sacrificing their deposits. This is a novel security feature.
4. (S) Scalability.
ブロックチェーン上に、フルノードが存在しなくても、動作することができる。
つまり、すべてのノードが、検証者も含め、トランザクションの履歴と状態の小さな断片だけを保持している状態であっても、ブロックチェーンが動作するような状況である。
The blockchain must be able to operate with no full nodes, ie., in a situation where all nodes, including validators, store and verify only a small fraction of the transaction history and state.
5. (D) Decentralization.
システムは、あらゆる”super-nodes” に頼らずと機能する。( ”super-node” は一般(平均的)ユーザーが設定して到達することのできないものを指します。) つまり、
ノートパソコンなどの汎用機器以上のものはもはや何もいらないような非中央集約化の状況を指します。
The system can function without inherently relying on any “super-nodes” that would be out of reach for the average user to set up. Ie., it can operate off nothing more than a sufficiently large set of consumer laptops, thereby promoting high decentralization.
6. (IC) Inter-shard communication.
違う「破片」上のアプリケーションは互いに操作できる状況になければならない。特に、一つのアプリケーションが複数の「破片」を横断して存在する状況でなければならない。
Applications on different shards must be able to interoperate. Particularly, it must be possible for a single application to exist across multiple shards.
7. (RCC) Recovery from Connectivity Catastrophe.
システムは、たとえ、全ノードあるいは検証者の50%超が突然オフラインになるような状況であっても、処理が滞らず、回復することができる。The system can recover and proceed even if >50% of all nodes or validators are suddenly knocked offline.
8. (CR) Censorship resistance.
プロトコルは、全「破片」を横断する大多数の検証者が結託し、望まざるトランザクションをチェインに取り込み、finalize するのを防ぐようなことを企てたとしても、その行為に対して耐性を持つべきである。
The protocol should be resistant to even a majority of validators across all shards colluding to prevent undesired transactions from getting into the chain or being finalized.
第2節では、(POS)と(FB)だけを達成したアルゴリズムについて記述します。
第3節では、この基礎アルゴリズムに(F)を加え、拡張します。
第4節では、再び部分的に(S), (D), (IC)を満たすアルゴリズムについて議論します。
より強い(S), (D), (IC)を満足するものは、(RCC),(CR)も同様に、先の仕事とし、将来のリリースにおいて、もう一度議論することとします。
In Section 2 we describe a base algorithm that achieves only (POS) and (FB). In Section 3 we augment this base algorithm to add (F). In Section 4 we again augment the algorithm to partially satisfy (S), (D), and (IC). Stronger satisfaction of (S), (D), (IC), as well as any degree of (RCC) and (CR), are left as future work and will be revisited in future releases.
定数は大文字で LIKE_THIS のように書きます。 その値は Appendix Aにまとめてあります。変数は、like_this のように小文字で表示しますが、XやB1といったただ一つの大文字を用いて表す場合があります。
Constants are written in capitals LIKE_THIS; the values are given in Appendix A. Variables are lowercase like_this, though sometimes single capital letter names like X and B1 are also used for variables.
# Minimal Proof of Stake
Note: an understanding of Ethereum 1.0 is assumed in this and later sections
以下に、(POS)と(FB)を満たす最小限の proof of stake アルゴリズムをつくります。
我々は、CASPER_ADDRESS アドレスに、ある "Casper contract" の存在を特定します。
"Casper contract" は検証者のリストを保持するものです。
それは、pos の genesis block に含まれますが、特別な権利を持ちません。
"Casper contract" の呼び出しが、ブロックヘッダを有効化する最初のステップとなります。
最初の検証者の集合はその genesis block で定義され、次の関数を通して、修正が施されます。
- `deposit(bytes validation_code, bytes32 randao, address withdrawal_address)`: 検証者追加の処理を開始し、少なくとも MIN_DEPOSIT_SIZE ether のデポジットを必要とします。送信者は次の3つを特定します。
- ブロックの検証や送信者が署名したコンセンサスメッセージの検証に利用するある一つの "validation code"
- randao コミットメント(リーダー選定に使用される32バイトのハッシュ値)
- 仮装採掘の結果の資金が向かうアドレス
We create a minimal proof of stake algorithm satisfying (POS) and (FB) as follows. We specify that at address CASPER_ADDRESS there exists a "Casper contract", that keeps track of the validator set. The Casper contract is included in the genesis block but has no special privileges. Calling the Casper contract is the first step in validating a block header. The initial validator set is defined in the genesis block, and can be modified through the following functions:
- `deposit(bytes validation_code, bytes32 randao, address withdrawal_address)`: begins the validator addition process and requires a deposit of at least MIN_DEPOSIT_SIZE ether. The sender specifies:
- a piece of "validation code" (EVM bytecode) that will be used to verify blocks and other consensus messages signed by it.
- a randao commitment (a 32-byte hash used in leader selection; see below).
- the address that the eventual withdrawal goes to.
形式的には、validation code の仕様は、一つの block header hash と一つの signature を引数にとり、その signature が有効ならば、1 を返し、そうでなければ 0 を返す関数です。
この(validation code を各検証者が実装するという)メカニズムによって、
各検証者はどんな署名形式をも使うことができます。例えば、検証者は、多数の秘密鍵から署名を検証したり、
量子耐性が望ましいとなれば、Lamport 署名を利用すること等ができます。
このコードは、実行は外部の状態で不変なものであることを確約する新しい CALL_BLACKBOX opcode を利用したブラックボックスの環境下で実行されます。
(
自分が採掘したという署名に対する検証の方法を自由に各採掘者が選ぶことができる。
自分が採掘した時に、署名とブロックヘッダを提出するが、その検証には、
自分で提出した検証コードを皆に処理してもらう。
自らの公開鍵の情報を提供しなければ、自分の持つ秘密鍵のアドレスに採掘の報酬が入っていることを皆が確約することはできない。
)
Formally speaking, the validation code implements a function that takes a block header hash and a signature. The code returns 1 if the signature is valid and 0 otherwise. This mechanism allows each validator to use any signature scheme, eg. validators can use validation code that verifies signatures from multiple private keys, use Lamport signatures if quantum-resistance is desired, etc. The code is executed in a black box environment using a new CALL_BLACKBOX opcode to ensure execution is invariant of external state.
デポジット関数に置いて提供される randao の値は、sha3 ハッシュの長い鎖の計算結果です。つまり、ある秘密の値 x に対し、`sha3(sha3(sha3(.....(sha3(x))...)))` の返り値です。
各検証者の randao value は Casper コントラクトのストレージに保存されます。
Casper contract は、globalRandao と呼ばれる bytes32 型の変数も含み、その初期値は 0 とします。
The randao value provided in the deposit function is the result of computing a long chain of sha3 hashes, ie. `sha3(sha3(sha3(.....(sha3(x))...)))` for some secret x. Each validator’s randao value is saved in the Casper contract's storage. The Casper contract also contains a bytes32 variable called globalRandao, initialized to zero.
もし、全てのパラメータが承認されれば、これにより新しい検証者が、その次のさらに後の epoch の開始から、検証者の集合に追加されます。つまり、デポジットが epoch n でコールされたなら、その検証者は epoch n+2 の開始から検証者の集合に加わります。ここで epoch とは、EPOCH_LENGTH ブロック数の期間です。
validation code のハッシュ値 ( vchash とします。) は、validator ID として使われます。
全ての検証者は、異なるIDを持ちます。
If all parameters are accepted, this adds a new validator to the validator set from the start of the epoch after the next, ie. if deposit is called during epoch n, the validator joins the validator set at the start of epoch n+2, where an epoch is a span of EPOCH_LENGTH blocks.The hash of the validation code (called the vchash) is used as a validator ID; every validator must have a distinct ID.
Casper contract は他にも関数(Appendix B を参照)を含みます。
ここで関係のあるものとしては、
- `startWithdrawal(bytes32 vchash, bytes sig)`: 引き出しのプロセスを開始する。その検証者の検証コードをパスする署名が必要です。署名がパスすれば、その次のさらに後の epoch から検証者の集合からその検証者を引き出します。この関数はいかなる ether を引き出すものではありません。
- `finishWithdrawal(bytes32 vchash):` 検証者の ether 、報酬をプラスし罰則をマイナスしたもの(結果がマイナスであれば0)を特定された、検証者の引き出しアドレスに引き出します。これは、検証者が、動作中の検証者の集合から startWithdrawal 関数を使用して、少なくとも WITHDRAWAL_DELAY 秒前に引き出された限り有効です。
The Casper contract contains other functions (see Appendix B). Relevant here are:
- `startWithdrawal(bytes32 vchash, bytes sig)`: Begins the withdrawal process. Requires a signature that passes the validation code of the given validator. If the signature passes, then withdraws the validator from the validator set from the start of the epoch after the next. Note that this function does not withdraw any ether.
- `finishWithdrawal(bytes32 vchash):` withdraws the validator’s ether, plus rewards minus penalties (if the net result is negative, the withdrawn amount is zero), to the specified validator’s withdrawal address, as long as the validator has withdrawn from the active set of validators using startWithdrawal at least WITHDRAWAL_DELAY seconds ago.
Casper contract は次の関数を含みます
The Casper contract contains a function:
- `getValidator(uint256 skips)`: 与えられた引数(スキップ数)の後に次にブロックを作るものとして指定された検証者の検証コードを返します。例えば、getValidator(0) は、最初の検証者(通常そのブロックを作る検証者)を返し、getValidator(1) は二番目の検証者(もし最初の検証者がネットワーク利用不可であったときにブロックを作成する検証者)を返します。各検証者は ative な検証者の集合から擬似乱数を用いてランダムに選ばれ、各検証者のデポジットにより線形的に重み付けがなさた確率で選択が施されます。randomness 乱雑度合 は globalRandao の値からシードが与えられます。ブロックを公布するとき、ブロックヘッダは検証者の現在の randao の原像も含まなければなりません。この原像は、検証者が Casper contract に記録した randao に取りかえられ、 globalRandao の中へ XOR 排他的論理和が取られます。このように、毎度、検証者が一つのブロックを公布するたびに、検証者の randao の一つのレイヤを "剥がし" 、globalRandao が更新されます。
- `getValidator(uint256 skips)`: returns the validation code of the validator that is designated to create the next block after the given number of "skips", ie. getValidator(0) returns the first validator (the validator that would normally create the block), getValidator(1) returns the second validator (the validator that would create the block if the first is unavailable), etc. Each validator is pseudorandomly selected from the active validator set, with the probability of selection linearly weighted by each validator's deposit; the randomness is seeded by the Casper contract's globalRandao value. When publishing a block, the block’s header must also contain the preimage of the validator’s current randao. This preimage then replaces the validator’s saved randao value in the Casper contract, and is XORed into Casper’s globalRandao. Hence, each time the validator publishes a block it “unrolls” one layer of its randao and the globalRandao is updated.
これまでの議論により、ブロックが自身の extra_data フィールドとして含まなければいけないデータは次となります。
~~~
~~~
ここで、vchash は検証者のコードのハッシュ値で(検証者のIDとして使われます)、randao とは上記の通り 32-byte の randao ハッシュ原像を明示したものです。sig は検証者の署名で、任意の長さから作ることができます。(しかし、ブロックヘッダ全サイズは、有害な使い方を減らしたり、ライトクライアントにとって優しいのは 2048byte 以下のサイズです。)
So far, the data that a block must include in its extra_data field is:
~~~
~~~
Where vchash is the hash of the validation code (used as the validator ID), randao is the 32-byte randao hash pre-image reveal described above, and sig is the signature, which can be of arbitrary length, (however the total block header size is capped at 2048 bytes for light client friendliness and to mitigate abuse).
_ | - | -Seconds- | -after- | -block- | is | -published
---|---|---|---|---|---|---
_ | 0 | BLOCK_TIME | BLOCK_TIME + SKIP_DELAY * 1 | BLOCK_TIME + SKIP_DELAY * 2 | ... | BLOCK_TIME + SKIP_DELAY * k
Validators to accept blocks from | _ | getValidator(0) | getValidator(0) getValidator(1) | getvalidator(0) getValidator(1) getValidator(2) | ... | getValidator(0) ... getValidator(k)
Table 1: Which validators to accept blocks from.
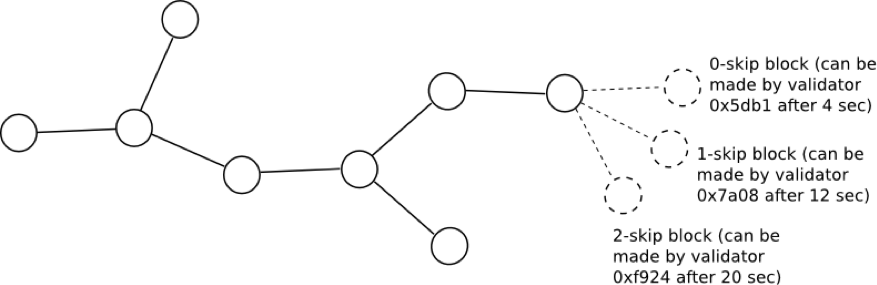
ある検証者のブロックが承認されるまでの最小の時間は、`BLOCK_TIME` `+` `SKIP_TIME` `*` `< number of skips >` です。実践に置いてこれが意味するのは、一度ブロックが公布されると、0-skip 検証者
The minimum time after which a validator’s block can be accepted is: `BLOCK_TIME` `+` `SKIP_TIME` `*` `< number of skips >`. This in practice means that once a given block is published, the 0-skip validator for the next block can publish after `BLOCK_TIME` seconds, the 1-skip validator after `BLOCK_TIME` `+` `SKIP_TIME` `*` `1` seconds, and so forth. If a validator publishes a block too early, other validators are to ignore it until the prescribed time, and only then process it. The distance between the short `BLOCK_TIME` and longer `SKIP_TIME` ensures that typical block times can be very short while still functioning under high network latency; arguments around the incentive compatibility of protocols using timestamps in this way are explored here.
## Dunkles ( ダークブロックについて )
もしある検証者があるチェーンに含まれる一つのブロックを生成したとすると、
彼らは、その epoch 間における active validator set の中における、全 ether と等価のブロック報酬を受け取り、
それは、`REWARD_COEFF` によって測られます。
If a validator produces a block that gets included in the chain, they receive a block reward equal to the total ether in the active validator set during that epoch, scaled by `REWARD_COEFF`,
`Block_reward(k) = REWARD_COEFF *` $ \sum _ {i=1} ^ n \text{netdeposit} _ {k,i} $ .
`REWARD_COEFF` はこのように基本的には、ある検証者がそのプロトコルに従うための "ブロックあたりの期待される利益率
" となります。 そのブロック時間で割り、~32 million をかけることで、年利率の近似値がえられます。
もし検証者がチェーンに含まれないブロックを生成した時は、このブロックのヘッダは後の(その検証者が引き出しを行うまでの)任意の時点に置いてチェーンに含みえ、これは Casper contract の includeDunkle(header:str) 関数を通して、"dunkle" 「ダークな」ものとして扱われます。
これはその検証者がそのブロック報酬(その dunkle を含んだ検証者は罰則(ペナルティ)の一部を受けます。)と等価のお金を消失(検証者のデポジットから差し引かれます)を引き起こします。報酬と罰則が等価であれば、分別のある検証者は50%より大きい割合でブロックがチェーンの一部となるであろう、という場合にかつその時に限り、ブロックを発行するでしょう。
これは、全ての時間における任意のブロックのてっぺんに発行する行為をげんなりさせるものです。
検証者の増加し続けるデポジット、報酬と罰則を含むもの、は Casper contract の「状態」に保存されます。
もし、検証者の netdeposit が MIN_DEPOSIT_SIZE を下回れば、startWithdrawal 関数が自動的に呼ばれます。
`REWARD_COEFF` thus essentially becomes an "expected per-block interest rate" for a validator complying with the protocol; divide by the block time and multiply by ~32 million to get the approximate annual interest rate. If a validator produces a block that does not get included in the chain, then this block's header can be later included in the chain at any point (up until the validator calls withdraw) as a "dunkle" via the Casper contract's includeDunkle(header:str); this causes the validator to lose money (it is subtracted from its deposit) equal to the block reward (the validator that includes the dunkle is awarded a cut of the penalty). Given an equal reward and penalty, a Rational validator will publish a block if and only if it is >50% certain that the block will make it into the chain; this discourages publishing atop every chain all the time. The validators’ cumulative deposits, including rewards and penalties, are stored in the state of the Casper contract. If a validator’s net deposit goes below MIN_DEPOSIT_SIZE, startWithdrawal is automatically called.
"dunkle" メカニズムの目的とは、proof of stake における "nothing at stake" 問題をを解決することです。
もし、報酬だけがあり、罰則がなければ、分別のある(合理的な)検証者であれば全ての可能なチェーンのてっぺんにブロックを発行するでしょうし、このようにして canonicity が失われます。
proof of work に置いては有効なブロックを見つける高コストが、"main chain" のてっぺんでのみの発行が利益をもたらすということ、を必要とします。
(proof of work に置いては有効なブロックを見つける高コストが十分なものなので、"main chain" のてっぺんでのみの発行が利益をもたらします。)
The purpose of the "dunkle" mechanism is to solve the "nothing at stake" problem in proof of stake. If there are rewards but no penalties then a Rational validator will publish blocks atop every possible chain, thus losing canonicity. In proof of work, the high cost of finding valid blocks necessitates it’s only profitable to publish on top of the "main chain". The dunkle mechanism replicates the proof of work incentives by artificially penalizing publishing blocks which don’t get included in the main chain.
## The Fork-choice Rule
一定の(あるいは少なくとも一定サイズの)検証者の集合を仮定すれば、我々は簡単にチェーンの fork-choice rule を定めることができます。
- ブロックを数えます。
- 一番長い鎖が勝ちます。
しかしながら、検証者の集合が肥大縮小するような場合には、これはうまく行数、少数を支持する fork が、多数が支持する fork と同じ速さで生成することが可能です。これを考慮するために、我々は
- ブロックを数え、
- 各ブロックに対し、ブロック報酬による重み付けを行います。
これはブロック報酬は active validator らの net deposited ether に比例しているものであるからで、
一番たくさんの ether を持ったチェーンが選ばれます。
Assuming a constant (or at least constant-sized) validator set, we can easily define the fork-choice rule: count blocks; longest chain wins. However, when the validator set grows or shrinks, this will not work well, as a minority-supported fork still can produce blocks just as quickly as a majority-supported fork. To account for this, we still count blocks, but weigh each block by its block reward. Since block rewards are proportional to the active validators’ net deposited ether, the chain with most ether at stake is chosen.
我々はこの規則を直感的には、「損失値としての fork-choice 」として理解することができます。
この原理は、出資金 stake において最もたくさんの ether を検証者が預けているものを選ぶというものです。
つまり、検証者が一番たくさんのお金をコミットしたチェーンです。
我々はこれを、検証者がお金を最も失わなくて済む fork を選ぶことと等価だと見ることができます。
これが、ブロック報酬の重み付けがされたブロックの一番長いチェーンと等価であるという証明は、Appendix C に与えています。
We can intuitively understand this rule as fork-choice as value-at-loss. The principle is that we select the fork on which validators have put the most ether at stake, ie. the chain such that validators have committed the most money. We can equivalently view this as choosing the fork in which validators lose the least money. The proof that this is equivalent to the longest chain with blocks weighted by block reward is given in Appendix C.
# Adding Finality
次に finality (F) を追加します。
デフォルトの検証者の戦略は高い値のコミットを作成する
Next we add finality (F). The default validator strategies should be conservative in making high-value commitments so the risk for honest validators should be very low. We do this as follows: Inside the block header, in addition to pointing to the hash of the previous block, a validator may now also claim the probability that some previous block finalization_target will be finalized. This claim is phrased as a bet, as in "I believe that block 0x5e81d... will be finalized, and I am willing to lose V_LOSS in all histories where this is false provided that I gain V_GAIN in all histories where this is true". The validator chooses the odds, and V_LOSS and V_GAIN are computed as follows (where total_validating_ether is the net amount of ether deposited by the active validator set:
~~~
BASE_REWARD = FINALITY_REWARD_COEFF * total_validating_ether
V_LOSS = bet_coeff * odds * BASE_REWARD
V_GAIN = bet_coeff * log2(odds) * BASE_REWARD
~~~
Notice that for any finality bet, the gains from being right are dwarfed by the losses from being wrong, ie., for all bets, `V_GAIN << V_LOSS`.
finalization_target starts off null, though during block 1 it is set to block 0. At genesis, `bet_coeff=1` and `cached_bet_coeff=0`.When processing every block, we update:
~~~
bet_coeff = max(MIN_BET_COEFF, BET_COEFF_DECAY_FACTOR * bet_coeff)
cached_bet_coeff *= BET_COEFF_DECAY_FACTOR
~~~
Constant MIN_BET_COEFF ensures there is some minimum incentive to bet. In addition to V_GAIN, when producing a block, a validator gains `BASE_REWARD * LOG_MAXODDS * cached_bet_coeff`, where `LOG_MAXODDS` is the logarithm of the maximum allowed odds. Once a block is finalized, validators get rewards from it as though they henceforth bet with maximum odds; this ensures Rational validators finalize blocks as soon as possible.
When the Casper contract determines that the finalization_target has been finalized (ie. the block’s total value-at-loss exceeds `FINALIZATION_THRESHOLD_PROPORTION*total_validating_ether` ), we set the new finalization_target to one of the descendent blocks, we set:
~~~
cached_bet_coeff += bet_coeff
bet_coeff = 1
~~~
Starting from the new finalization target, the finalization process begins anew. If there is a short-range fork, there may be finalizations going on for multiple blocks at the same time, which may even be at different heights. This would happen if, for example, block A is finalized in both blocks B1 and B2, with the result that in the B1 chain, B1 is the new finalization target, and in the B2 chain, B2 is the new finalization target. However, given the default validator strategy of betting on the block with the highest value-at-loss backing it, we expect the process to converge toward choosing exactly one of the competing blocks (the convergence arguments are the same as those for minimal proof of stake).
When finalization starts for a block, we expect the odds will be low, signifying validators' fear of short-range forks, but that over time the typical offered odds will increase with validator bets increasing faster if they see other validators placing high-odds bets. Given this self-reinforcing safety of bets, we expect the value-at-loss on the block will increase exponentially, thereby hitting the finalization threshold in logarithmic time.
To achieve (F), we add two new values to the block header’s extra_data field:
~~~
~~~
Where blockhash is a prior block hash that the bet is made on, and logodds is a 1-byte value representing the odds in logarithmic form. For a given odds odds:1, the logodds formula is: logodds = round(8 * log2( odds )). Ie., the minimum odds 1:1 corresponds to logodds 0x00, and the maximum odds 232:1 corresponds to logodds 0xFF.
We do not allow validators total freedom in setting odds. The reason is that if there are two competing finalization targets, B1 and B2 (ie. there exist two chains, in one of which finalization_target is set to B1 and in the other finalization_target is set to B2, and B1 != B2), and a consensus starts forming around B1, then a malicious validator may suddenly place a high-odds bet on B2, with sufficient value-at-loss to sway the consensus, and thereby trigger a short-range fork. Hence, we limit odds by limiting V_LOSS, using the following rules. Let V_LOSS_EMA be an exponential moving average, set as follows. At genesis, V_LOSS_EMA=block reward. Then, during each block,
~~~
V_LOSS_EMA *= ((V_LOSS_MAXGROWTH_FACTOR - SKIPS - 1) / V_LOSS_MAXGROWTH_FACTOR) + V_LOSS
V_LOSS = min( V_LOSS, V_LOSS_EMA * (V_LOSS_MAXGROWTH_FACTOR + 1) )
~~~
where `SKIPS` is the minimum skip-index of that block’s validator and V_LOSS is the V_LOSS selected in that block.
This rule is designed to incorporate a safety constraint: a validator can risk at most ( V_LOSS_GROWTH + 1) * x after at least `1 / (V_LOSS_GROWTH + 1)` of (a sample of) other validators have risked x. This is similar in spirit to the precommitment/commitment patterns in Byzantine-fault-tolerant consensus algorithms where a validator waits for two-thirds of other validators to take a step before taking the next step. It also gives some buffer against even a majority collusion engaging in "griefing" attacks (ie. getting other validators to place large value-at-loss behind a block and then pushing the consensus the other way). In fact, with `V_LOSS_GROWTH = 0.5`, the collusion would lose money faster than the victims, which ensures that even under hostile-majority conditions bad actors can over time be "weeded out".
If a block is included as a dunkle, the bets are processed and both penalties and rewards may result. For example, in Figure 2 there are two blocks A1 and A2 that are competing finalization targets, and two blocks B1 and B2 (both with A1 as an ancestor), and a validator makes a block C on top of B1 making a bet for A1, then if B2 ends up being in the main chain, B1 and C will become dunkles, and so C will be penalized for "getting it wrong" on B1 but still rewarded for "getting it right" on A1.
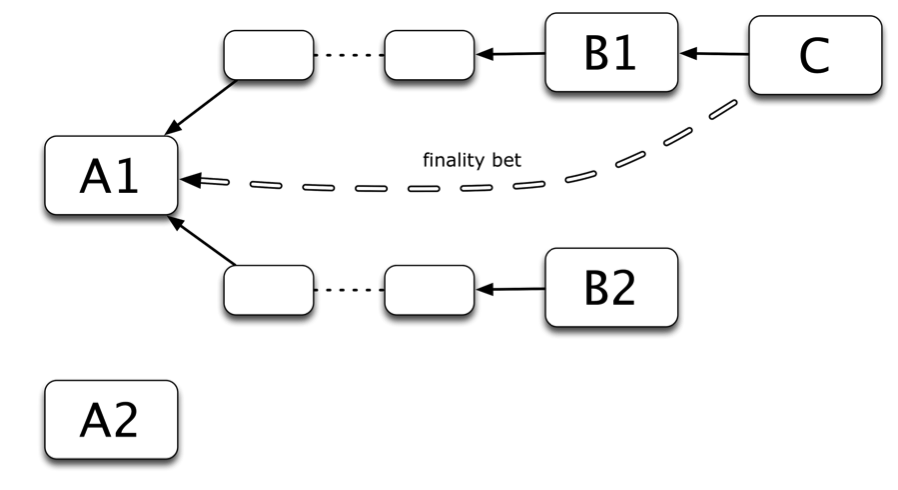
However, suppose that the `V_LOSS` in C is such that although `V_LOSS < V_LOSS_MAX` if B1 is included, but if B2 is included, `V_LOSS > V_LOSS_MAX`. Then, in order to preserve the desired value-at-loss properties, we institute an additional penalty: we penalize the validator by `V_LOSS - V_LOSS_MAX` even if their bet is correct. Thereby, we effectively decompose the bet of size V_LOSS into a combination of (i) a bet with value-at-loss `V_LOSS_MAX` and (ii) pure destruction of `V_LOSS - V_LOSS_MAX`, thereby ensuring that such an excessively sized bet can shift the fork choice rule by at most `V_LOSS_MAX`. This means that finality bets are unfortunately not "pure", as a bet on some block can lead to a penalty even if that block is finalized if too many of its children get forked off. The loss of purity in the betting model for the gain of game-theoretic purity in the value-at-loss fork-choice rule is deemed an acceptable tradeoff .
3.1 Scoring and strategy implementation
The value-at-loss scoring can be implemented using the following algorithm:
1. Keep track of the latest finalized block. If there are multiple, return a big red flashing error, as this means that a finality reversion event has happened and the user should probably use extra-chain sources to determine what's going on.
2. Keep track of the set of all finalization candidates that are children of the latest finalized block. For each candidate, keep track of the value-at-loss supporting it.
3. Starting from the latest finalized block, keep track of the longest chain through each finalization candidate and its length. For example, in Figure 3, we would keep track of chains (A,B,D,E,F,H,J,L,N) and (A,B,D,E,G,I,K).
4. The "total weight" of a chain is the value-at-loss of its finalization candidate ancestor plus the length of the chain times the block reward. If there is no finalization candidate in the chain, then the length of the chain times the block reward is used by itself. The "head" is the latest block in the chain with the highest total weight.
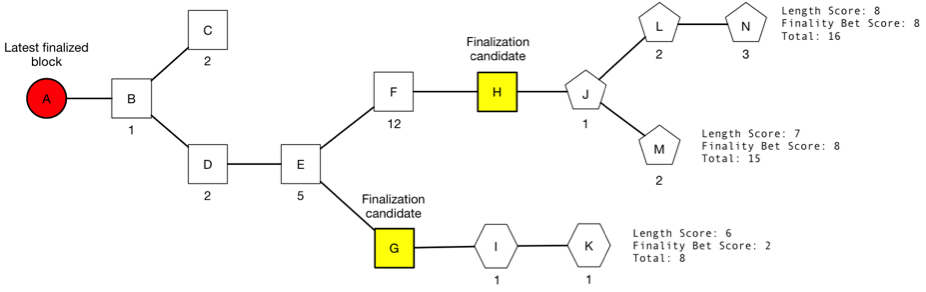
The `V_LOSS` values are for illustrative purposes; in reality they would not grow this quickly and a much higher `V_LOSS` on A would be required for B or C to become finalization candidates. The square blocks placed finality bets on A. The pentagon blocks are placing finality bets on H, and the hexagon blocks are placing finality bets on G.
A simple validator strategy is to try to create blocks only on the head, and to make finality bets where the value-at-loss is 80% of the prescribed maximum.
## Light-client syncing
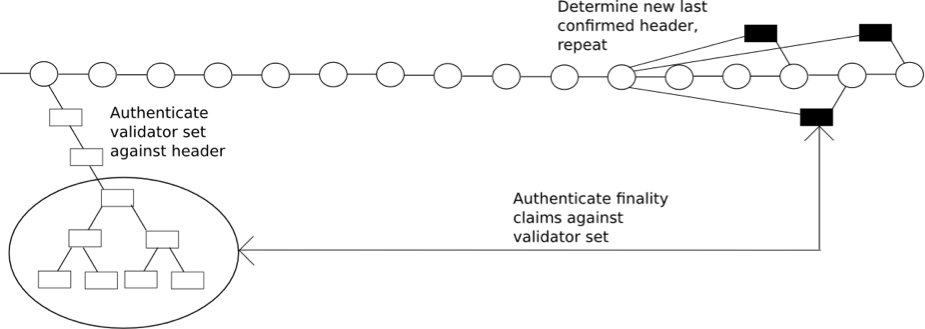
This finality mechanism permits a very fast light-client syncing algorithm. It is:
1. Let S be the latest state you have confirmed (initially, the genesis state).
2. Ask the network for the latest finalization target within S’s epoch or the following epoch (remember: the finalization target is the block during which the protocol deems the previous finalization target to be finalized). Call the latest finalization target F_n and the previous finalization target F_p
3. Ask the network for the k blocks right before F_n. These blocks will make huge bets on finalizing F_p.
4. Authenticate the validators of those k blocks. Do this by making Merkle branch queries against:
a. your already-finalized state to verify their presence in the validator set
b. the pre-state of the first of the k blocks, to verify that they were selected correctly.
5. If both checks pass, set S to the post-state of F_p. Otherwise, _______________.
6. Repeat steps 1–5 until you reach the latest finalized block. Once there, use the normal strategy (from Section 3.1) to find the head of the chain.
Each iteration of steps 1–5 could likely be optimized down to two network requests and a few seconds of computation, thus light-verifying an entire day's worth of blocks in 1-2 minutes. .
# Scalability via Sharding
To achieve scalability (S), we expand from having one single blockchain to multiple intertwingled chains, which we call "shards". There are `NUM_SHARDS` shards, indexed `0` to `NUM_SHARDS - 1`. Shard 0 is uniquely special and operates as a regular proof-of-stake blockchain with finality per above. All finality bets are made in shard 0. When a bet is made, it is stored, but the bet is evaluated only after the end of the subsequent epoch (ie., finality bets made during epoch n+1 are evaluated, in shard 0, at the start of epoch n+3).
Shards `1` ... `NUM_SHARDS - 1` work differently. At the start of every epoch, a random set of VALIDATORS_PER_SHARD validators are selected for each shard. These validators are assigned to that shard for the next epoch (ie. the validators for epoch n+1 are assigned at the start of epoch n). getValidator(skips), when called to determine the validator within one of these shards, picks randomly with a uniform distribution (the deposit-size weighting was done when selecting the validators for each shard) from one of the shard’s validators.
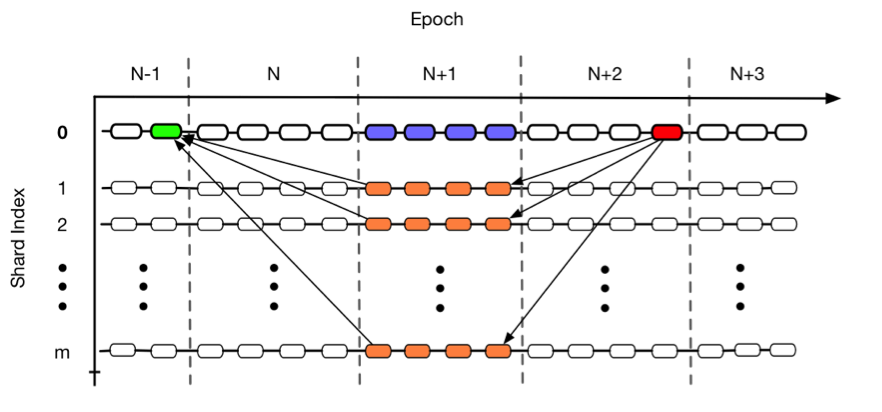
In the orange blocks, each selected validator publishes blocks on its respective `shard(s)`. In the blue blocks, each selected validator places finality bets on all other shards (indices 1 … m). In the red block, the selected validators are rewarded based upon their orange-block publishings and their blue-block bets. Diagonal lines are required cross-shard communication.
If a validator has been selected for a shard, that validator must call the `registerForShard(bytes32 vchash, uint256 shard, uint256 index, bytes32 randao)` function of the Casper contract, where vchash is the validator's validation code hash, shard is the shard’s index, index is a value where 0 <= index < VALIDATORS_PER_SHARD where getShardValidator(uint256 shard, uint256 index) returns the given vchash, and randao is a randao commitment. The function registerForShard creates a receipt. Passing this receipt toconfirmReceipt(uint256 receiptId) inducts the validator into the shard’s validator set for that epoch.
Though it relies on a separate source of randomness, getShardValidator follows similar logic as getValidator. getShardValidator’s randomness is derived as follows:
1. Within each epoch, for 0 <= k < 24, keep track of the number of times that the k’th rightmost bit of globalRandao is equal to 1 minus the number of times that the k’th bit is equal to 0.
2. At the end of each epoch, let bitstring combinedRandao be such that for all 0 <= k < 24, the k’th bit is set to 1 if during that epoch there were more 1s in the globalRandaos and 0 otherwise. Bits above the 24th are all zero. Use sha3(combinedRandao) as the source of randomness.
In order not to overly bog down light-clients, cross-shard finality bets are NOT in the block header; instead, the validator is expected to include a transaction calling `registerFinalityBets(bytes32[] hashes, bytes[] logodds)` within every block it publishes. registerFinalityBets expects `NUM_SHARDS` hashes and a byte array NUM_SHARDS bytes long with each byte representing the logodds for the corresponding block hash.
The typical validator’s workflow would be to maintain a "full node" for shard 0, as well as maintain a full node for any shards it is later assigned to. When a validator is assigned to a shard, it downloads the state of the shard using Merkle tree proofs and ensures it has fully downloaded the state before validating any blocks. For that epoch, it will validate blocks for that shard and publish blocks.
Any active validator, regardless of whether it’s been selected to validate any shard, may place finality bets on all shards (even if it is validator on that shard), where choose their odds by examining
- what the longest chain is on each shard
- other validators' finality bets
- various secondary heuristics and mechanisms that try to catch successful 51% attacks within a shard (eg. fraud proofs). Note that the probability of being assigned to any given shard is proportional to the validator's deposited ether; hence, a validator that deposits twice as much ether will be assigned to do twice as much computation. This property is considered desirable, as it reduces pooling incentives and introduces an element where processing transactions and storing the blockchain itself becomes a form of " proof of work" within our proof of stake system.
The sampling mechanism is to ensure the system is secure against attackers that have even up to ~33-40% of the total deposited ether (only 40% because attackers with 40-50% of the total deposits may "get lucky" on some shard). Although on each shard only a few validators actually verify transactions; because the sampling is random, attackers cannot choose to concentrate their stake power on a single shard, a fatal flaw of many proof-of-work sharding schemes. Even if attackers are able to constitute the great majority of a single shard’s validators, there remains a second line of defense: if the off-shard validators see evidence of an attack, then they can refuse to make finality bets on any suspicious chains, instead confirming the chain that appears most honest. Moreover, if the attackers try to create a chain out of invalid blocks, off-shard validators can detect this, and then start temporarily validating blocks on the suspect shard to ensure that they are only placing finalization bets on valid blocks.
## Cross-shard communication
Applications will be able to interact across shards, but the possibilities are much more limited; synchronous cross-shard function calls and returns are not going to be possible in the same way that they will be within a shard and that they are in the current Ethereum. While it will be possible to write many kinds of applications in a cross-shard way, we expect the majority of smaller applications to each base themselves within a single shard for convenience. Operations that can be conducted across shards are those operations that can be done asynchronously - moving funds, entering into a contract, sending an instruction (that does not require an immediate response), etc; operations that involve taking actions based on immediate responses or that otherwise demand strong synchrony cannot be done easily between shards.
Cross-shard communication works as follows:
1. We create a new opcode ETHLOG which takes two arguments It creates a log whose stored topic is the empty string and whose data is a 64-byte string containing the destination and the value.
2. We create a new opcode `GETLOG`, which takes as a single argument an ID which is interpreted as `block.number * 2**64 + txindex * 2**32 + logindex` (where txindex is the index of the transaction that contained the log in the block, and logindex is the index of the log in the transaction's receipt). When the opcode is called, VM execution tries to obtain that log, stores a record in the state saying that the log has been consumed, and places the log data into memory so that further VM execution can manipulate the data. If the log has the empty string as a topic, this also transfers the ether to the recipient. To successfully obtain a log, the transaction calling this opcode must reference the log ID.
The consensus abstraction is no longer a single chain; rather, it is a list of distinct chains/shards, `c[0]` ... `c[NUM_SHARDS - 1]`. The state transition function is no longer stf(state, block) -> state'; rather, it's stf(state_k, block, r_c[0] ... r_c[NUM_SHARDS - 1]) -> state_k' where r_c[i] is the set of receipts from shard i from at least ASYNC_DELAY blocks ago.
There are several ways to "satisfy" this abstraction. One is the "everyone is a full node" approach: every node stores the state of all shards and thereby every node has enough information to compute all state-transition functions. However, this does not scale.
A more scalable strategy is the "medium node" approach: a typical node fully validates shard 0 and moreover is selected to fully validate a few additional shards. It then chooses to be a light client for all other shards (this is mandatory; one must at least be a light client on every shard in order to validate cross-shard receipts). When computing the state transition function, it needs the old receipts, however it does not store them; instead, we add a network protocol rule requiring every transaction to be sent along with Merkle proofs of all receipts the transaction statically references. Here it becomes clear why static referencing is required - if an arbitrary GETLOG operation can be made at runtime, fetching logs would be bottlenecked multiple times by network latency, and this latency would encourage clients to store all historical logs locally, which defeats (S).
Note that importing these Merkle proofs from one shard directly into the other shard is never required; instead, the proof-passing logic is all done at the validator level with each validator having easy access to all Merkle-proven information. Finally, the long ASYNC_DELAY reduces the likelihood that a reorganization in one shard will require an intensive reorganization across many shards.
If shorter delays are desired, one option is an in-shard betting market, ie. in shard j A can make a bet with B saying "B agrees to send 0.001 ETH to A if block X in shard i is finalized, and in exchange A agrees to send 1000 ETH to B if that block is not finalized". Casper deposits can be dual-used for this purpose - even though the bet itself happens inside of shard j, information about A losing would be transmitted via receipt to shard 0 where it can then transfer the 1000 ether to B once A withdraws. B would thus gain confidence that A is convinced enough to bet that the block will be finalized, and also gains a kind of insurance against A's judgement failing (though if the dual-use scheme is imperfect, as if A is malicious they may lose their entire bet and so have nothing to give B).
This sharding scheme has a scalability limitation proportional to the square of a node's computing power, for two reasons. First, there’s a minimum amount of processing to compute rewards on shard 0; this amount is proportional to the number of shards. Second, all validators need to be at least light clients of all shards in order to validate cross-shard receipts. Hence, if nodes have N computing power, then there should be O(N) shards with each shard having O(N) processing capacity, for a net total capacity of O(N2). Scaling better than this will require a more complex sharding protocol and composing claim validations in some kind of tree structure; this is for future work.
# Future work
- Reduce the `ASYNC_DELAY` in such a way that cross-shard receipts are available as soon as the other shard is finalized.
- Reduce the `ASYNC_DELAY` to something as low as several times network latency. This allows for much smoother cross-shard communication but at the cost of a reorg in one shard potentially triggering reorgs in other shards; mechanisms need to be devised to effectively mitigate and handle this.
- Create a notion of "guaranteed cross-shard calls". This comes in two components. First, there is a facility that allows buying "future gas" in some shard, giving them insurance against gas supply shocks (possibly caused by an attacker transaction-spamming the network) and second, a mechanism where if a receipt from shard i to shard j is made, and there is gas available, then that receipt must be included as quickly as possible or else validators that fail to include the receipt get penalized (with penalties increasing quickly to eventually equal the validator's entire deposit). This ensures that if a cross-shard receipt is made, that receipt will be processed within a short (perhaps < 10 blocks) timeframe.
- Design a sharding scheme that scales better than `O(N2)`.
- Look into atomic transactions theory and come up with feasible notions of synchronous cross-shard calls.
# Acknowledgements
Special thanks to:
- Gavin Wood, for the "Chain Fibers" proposal
- Vlad Zamfir, for ongoing research into proof of stake and sharding, and particularly the realization that state computation can be separated from block production
- Martin Becze, for ongoing research and consultation
- River Keefer, for reviewing
# Appendix
A. Constants
Proof of Stake
- `BLOCK_TIME`: 4 seconds (aiming on the less ambitious side to reduce overhead)
- `CASPER_ADDRESS`: 255
- `EPOCH_LENGTH`: 10800 seconds (ie. 12 hours under good circumstances)
- `MAX_DEPOSIT_SIZE`: 2**17 ether
- `MIN_DEPOSIT_SIZE`: 32 ether
- `REWARD_COEFF`: (3 / 1000000000) * BLOCK_TIME
- `SKIP_TIME`: 8 seconds (aiming on the less ambitious side to reduce overhead)
- `WITHDRAWAL_DELAY`: 10000000 seconds (ie. 4 months)
Finality
- `BET_COEFF_DECAY_FACTOR`: 0.999 (ie. 1.1 hours under good circumstances)
- `FINALITY_REWARD_COEFF`: (0.6 / 1000000000) * BLOCK_TIME
- `FINALIZATION_THRESHOLD_PROPORTION = 0.666` (the proportion of total_validing_ether that must be exceeded for a block to be finalized)
- `LOG_MAXODDS`: log2( min[2**32, MAX_DEPOSIT_SIZE / BASE_REWARD] )
- `MIN_BET_COEFF`: 0.25
Sharding
- `ASYNC_DELAY`: 10800 seconds (ie. 12 hours under good circumstances)
- `NUM_SHARDS`: 80
- `VALIDATORS_PER_SHARD`: 100
B. Function Prototypes of the Casper Contract
Below is the full specification of the Casper contract’s functions, internal variables, etc.
~~~
>>>INSERT HERE<<<
~~~
registerForShard(bytes32 vchash, uint256 shard, uint256 index, bytes32 randao)
C. Proofs
- “The proof that this is equivalent to the longest chain with blocks weighted by block reward is given in Appendix C.”
# TODO
- When happy with the constants, add a little bit of text in the appendix explaining each one rather than all of the explanations being inline.
- When happy with the full Casper Contract, include the function prototypes for every Casper function in Appendix B.
- When 95% happy with the content, render this into gorgeous print-worthy LaTeX. OMG we’re going to be so adult.